3: Metadatos
3.1 Introducción
3.1.1 Metadatos son aquellos datos estructurados que aportan inteligencia en favor de operaciones más eficientes aplicadas a los recursos o fuentes de datos, operaciones como la preservación, la transcodificación, el análisis, el descubrimiento y el uso. Los metadatos ofrecen mayor rendimiento en entornos en red, pero son igualmente necesarios en cualquier entorno de almacenamiento y preservación digital. Los metadatos instruyen a los usuarios, sean éstos humanos o programas informáticos, sobre cómo interpretar los datos. Son cruciales para la comprensión, coherencia y funcionamiento exitoso de cualquier encuentro con un objeto archivado en cualquier momento de su ciclo de vida, así como con cualesquiera objetos asociados o derivados de él.
3.1.2 En términos funcionales, los metadatos pueden considerarse como «declaraciones esquematizadas sobre los recursos: esquematizadas por ser interpretables por máquinas (así como inteligibles por humanos); declaraciones porque implican una afirmación sobre un recurso por parte de un agente particular; recursos porque cualquier objeto identificable puede disponer de metadatos asociados» (Dempsey: 2005). Estas declaraciones esquematizadas (o codificadas), conocidas también como «instancias» de metadatos, pueden ser muy simples, como por ejemplo un identificador universal del recurso (URI)6 definido entre antilambdas <> a modo de contenedor o envoltorio y un espacio compartido de identificadores o nombres.7 Es habitual que los metadatos se vuelvan muy elaborados y adopten un aspecto modular, que comprendan numerosos contenedores dentro de contenedores, envoltorios dentro de envoltorios, cada uno en función de una serie de diferentes espacios de nombres y agrupados en diferentes etapas de un flujo de trabajo y durante un largo periodo de tiempo. Sería de lo más inusual que una sola persona crease, en una única sesión, una instancia de metadatos definitiva y completa para un objeto digital dado.
3.1.3 Independientemente de la cantidad de versiones de un mismo fichero de audio que puedan crearse a lo largo del tiempo, todas las propiedades significativas del objeto archivable deben permanecer inalteradas. El mismo principio vale para los metadatos embebidos en el objeto (ver la sección 3.1.4). Sin embargo, los datos acerca de cualquier objeto pueden cambiar con el tiempo: se descubre nueva información, evolucionan las opiniones y la terminología, los proveedores de información mueren y los derechos expiran o o se renegocian. Por todo ello a menudo es conveniente mantener separados los ficheros de audio y todos o parte de sus metadatos almacenados en ficheros, estableciendo vínculos adecuados entre ellos y actualizando los metadatos a medida que lo hacen la información y los recursos. Aunque es posible editar metadatos embebidos en un mismo fichero de datos, resulta pesado e incómodo, además de poco escalable y poco recomendable para grandes colecciones. La decisión de embeber los metadatos en los mismos ficheros de datos o en sistemas de gestión independientes dependerá en gran medida del tamaño de la colección, del grado de sofisticación del sistema de administración de datos y de la capacidad del personal responsable del archivo.
3.1.4 Los metadatos pueden integrarse en los mismos ficheros de audio, y de hecho esto constituye una solución aceptable para sistemas de almacenamiento digital (DSS - Digital Storage Systems) a pequeña escala (ver la sección 7.4, «Metadatos básicos»). El formato Broadcast Wave Format (BWF), estandarizado por la UER, Unión Europea de Radiodifusión (European Broadcasting Union, EBU), es un ejemplo de integración de metadatos de audio en el mismo fichero de audio. El formato BWF permite el almacenamiento de un número limitado de datos descriptivos dentro del estándar WAVE (fichero .wav - ver la sección 2.8, «Formatos de fichero»). Una ventaja de la opción de embeber los metadatos en el propio fichero reside en minimizar el riesgo de pérdida del vínculo entre metadatos y datos (audio digital) de un mismo objeto. El formato BWF permite la adquisición de metadatos de procesado, y muchas de las herramientas asociadas con este formato pueden adquirir los datos y rellenar con metadatos la parte correspondiente del fragmento 8 BEXT (Broadcast EXTension). Los metadatos pueden incluir la historia del proceso de codificación, vagamente definida en el mismo estándar BWF, con lo que se pueden documentar los procesos que llevaron a la creación del objeto de datos de audio digital. Esto presenta similitudes con la «entidad acontecimiento»9 definida en PREMIS (ver 3.5.2, 3.7.3 y fig.1). En el proceso de digitalización de fuentes analógicas puede usarse el fragmento BEXT de la cabecera del fichero BWF para almacenar información cualitativa sobre el contenido mismo del audio. Cuando se crea un objeto digital a partir de fuentes ya digitales, como DAT o CD, el fragmento BEXT puede destinarse a almacenar el listado de errores que pudieran haberse producido en el proceso de recodificación.
A=<ANALÓGICO> Información sobre el proceso del sonido analógico
A=<PCM> Información sobre el proceso del sonido digital
F=<48000, 44100, etc.> Frecuencia de muestreo [Hz]
W=<16, 18, 20, 22, 24, etc.> Longitud de palabra [bits]
M=<mono, estéreo, bicanal> Modo
T=<cadena de texto libre en código ASCII > Texto para comentarios
Campo para la historia de la codificación: BWF (<http://www.ebu.ch/CMSimages/en/tec_text_r98-1999_tcm6-4709.pdf>)
A=ANALÓGICO, M=Estéreo, T=Studer A820;SN1345;19.05;Bobina;AMPEX 406
A=PCM, F=48000, W=24, M=Estéreo, T=Apogee PSX-100;SN1516;RME DIGI96/8 Pro
A=PCM, F=48000, W=24, M=Estéreo, T=WAV
A=PCM, F=48000, W=24, M=Estéreo, T=2006-02-20 Datos del análisis sintáctico del fichero (parser)
A=PCM, F=48000, W=24, M=Estéreo, T=Datos de conversión del fichero 2006-02-20; 08:10:02
Fig. 1 Ejemplo de interpretación de la historia de codificación de una bobina original convertida a formato digital BWF mediante un sistema automatizado de bases de datos. National Library of Australia.
3.1.5 La Library of Congress ha estado trabajando en la formalización y expansión de varios fragmentos de datos en el fichero BWF. El documento Embedded Metadata and Identifiers for Digital Audio Files and Objects: Recommendations for WAVE and BWF Files Today es la versión más reciente del documento elaborado al respecto, disponible y abierto a comentarios en <http://home.comcast.net/~cfle/AVdocs/Embed_Audio_081031.doc>. El proyecto «AES-X098C: Administrative metadata for audio objects - Process history schema» es otro avance en la documentación de metadatos de proveniencia y procesado de datos.
3.1.6 Pueden hallarse sin embargo muchas ventajas en el hecho de mantener separados contenido y metadatos si se enmarcan en estándares como METS (Metadata Encoding and Transmission Standard - Estándar de codificación y transmisión de metadatos). Los procesos de actualización, mantenimiento y corrección son mucho más simples en un repositorio de metadatos separado de los datos. La ampliación de los campos de metadatos para la incorporación de nuevos requisitos o nueva información solo es posible en sistemas extensibles y separados. La creación de nuevas maneras de compartir información requiere un repositorio aparte de metadatos que pueda ser utilizado por sistemas diferentes. Para grandes colecciones, el lastre de mantener metadatos exclusivamente en las cabeceras de los ficheros BWF resultaría insostenible. Por ejemplo, el estándar MPEG-7 requiere que el contenido de audio y sus metadatos descriptivos estén separados, aunque ciertas descripciones (metadatos descriptivos) puedan ser multiplexadas10 con el contenido en forma de segmentos de datos alternados.
3.1.7 Por supuesto es posible encapsular un fichero BWF con una información de metadatos mucho más completa. Como la información contenida en el fichero BWF es fija y limitada, esta alternativa presenta las ventajas de ambas opciones. Otro ejemplo de integración son las etiquetas (tags) de metadatos necesarias en los ficheros de difusión para verificar que el objeto descargado o transmitido en tiempo real (streaming) es el deseado. Las etiquetas ID3, usadas en ficheros con formato MP3 para describir el contenido de la información e interpretadas hoy en día por la mayoría de reproductores MP3, permiten un conjunto mínimo de metadatos descriptivos. El mismo estándar METS ha sido estudiado como posible contenedor para el empaquetado conjunto de datos y metadatos, aunque el tamaño potencial de estos documentos plantea serias dudas sobre su viabilidad.
3.1.8 Se vislumbra una solución general para la separación de metadatos de su contenido (posiblemente con cierta redundancia si los contenidos incluyen a su vez metadatos) a partir de la tarea desarrollada en distintas universidades vinculadas a su vez con proveedores de la industria informática como SUN Microsystems, Hewlett-Packard e IBM. La idea es almacenar siempre la representación de un recurso mediante dos ficheros vinculados: uno que incluya los «contenidos» y otro que incluya los metadatos asociados al primero. Este segundo fichero incluye:
3.1.8.1 La lista de identificadores según todas las estructuras utilizadas. Se trata de hecho de una serie de «alias» asociados al nombre (URN - Universal Resource Name) y a la localización (URL - Universal Resource Location) del recurso.
3.1.8.2 Los metadatos técnicos (bits por muestra, frecuencia de muestreo, definición precisa del formato, y posiblemente la ontología asociada).
3.1.8.3 Los metadatos objetivos (coordenadas posicionales GPS, código de tiempo universal UTC, número de serie del equipo, operador, etc.).
3.1.8.4 Los metadatos semánticos.
3.1.9 En suma, la mayoría de sistemas deberán adoptar un enfoque práctico que permita a la vez embeber los metadatos en los ficheros de datos y mantenerlos separadamente, estableciendo prioridades (como por ejemplo, cuál de las dos opciones debe ser la fuente primaria de información) así como protocolos (normas para el mantenimiento de los datos) que aseguren la integridad del recurso almacenado.11
6 Del inglés, Uniform Resource Identifier (n. de los t.).
7 Del término informático inglés namespace (n. de los t.).
8 Del inglés chunk, fragmento o porción de metadatos incrustados en la cabecera de un fichero de datos (n. de los t.).
9 Traducción propuesta del inglés event entity en la versión española del diccionario PREMIS (n. de los t.).
10 O sea, alternadas secuencialmente en un fichero digital (n. de los t.).
11 Programas informáticos tales como BWF MetaEdit, desarrollado para la Iniciativa de Directrices para la Digitalización de las Agencias Federales (Federal Agencies Digitization Guidelines Initiative, FADGI) de la Biblioteca del Congreso de EUA, permiten una más fácil administración de los metadatos embebidos en la cabecera BEXT de los ficheros BWF, al presentarlos en formato de hoja de cálculo. BWFMetaEdit se puede descargar en <http://bwfmetadit.sourceforge.net> [último acceso 5 septiembre 2011] (n. de los t.).
3.2 Producción
3.2.1 El resto de este capítulo asume que en la mayoría de los casos los ficheros de audio y los de metadatos se crearán y gestionarán por separado, en cuyo caso la producción de metadatos involucrará aspectos logísticos como el movimiento eficiente de información, materiales y servicios a través de una red propia. Sin embargo, una colección de pequeñas dimensiones o un archivo en sus primeras fases de desarrollo, podrán quizá hallar ventajas en embeber metadatos en ficheros BWF completando un subgrupo del conjunto de metadatos referidos más adelante. Si se actúa con cuidado y con el debido conocimiento de los estándares y esquemas discutidos en este capítulo, esta aproximación es sostenible y plenamente migrable hacia un sistema completamente implementado como el descrito más abajo. Aunque la decisión de embeber la totalidad o parte de los metadatos en las cabeceras de los ficheros BWF, o bien gestionar solo una parte de ellos separadamente, queda en manos de los responsables de los archivos, el presente capítulo detallará la propuesta de creación y administración por separado. (ver también el capítulo 7, «Opciones a pequeña escala para sistemas de almacenamiento digital»).
3.2.2 Hasta hace poco los productores de información sobre grabaciones se encuadraban bien en equipos de catalogación, bien en equipos técnicos, y era poco habitual que sus resultados convergiesen. Pero las interrelaciones que propicia el trabajo en red han difuminado estas demarcaciones históricas. Ni que decir tiene que la incorporación de la logística a un flujo de trabajo operativo exitoso necesita la implicación de personas que entiendan las tareas y conectividad de los entornos en red. La producción de metadatos implica por tanto una estrecha colaboración entre ingenieros y técnicos de sonido, expertos en tecnologías de la información (Information Technology, IT) y especialistas en la materia. Requiere también de una dirección atenta que propicie una estrategia bien definida capaz de asegurar que los flujos de trabajo sean sostenibles y adaptables a la rápida evolución de las tecnologías y aplicaciones asociadas con la producción de metadatos.
3.2.3 Los metadatos son como los intereses: crecen con el tiempo. Si se crean metadatos exhaustivos y consistentes será posible utilizar este valor añadido en un número casi infinito de nuevas formas para dar respuesta a las demandas planteadas por diferentes tipos de usuarios, revisiones múltiples o búsquedas de datos (data mining).
Sin embargo, tanto los recursos como las disyuntivas de diseño técnico e intelectual implicadas en el desarrollo y administración de metadatos no son precisamente triviales. Los gestores de metadatos deben considerar, entre otros, los siguientes aspectos clave:
3.2.3.1 identificar qué esquema de metadatos o esquema extendido debería aplicarse para satisfacer las necesidades del equipo de producción, el repositorio mismo y sus usuarios;
3.2.3.2 decidir qué aspectos de los metadatos son esenciales para los fines que persiguen y el nivel de detalle necesario para cada tipo de metadatos. Dado que los metadatos se producen pensando en el largo plazo, seguramente siempre habrá un compromiso entre los costes de desarrollo y administración de metadatos que satisfagan las necesidades presentes y la creación de los suficientes metadatos para cubrir requisitos futuros, incluso inesperados;
3.2.3.3 asegurarse de que se aplican las versiones más actualizadas de los esquemas de metadatos.
3.2.3.4 La interoperatividad es otro factor clave: en la era digital, ningún archivo es una isla. Para facilitar la correcta transmisión de contenido a otro archivo o agencia se necesitan una estructura y sintaxis compartidas. Este es el principio rector de los estándares METS y BWF.
3.2.4 Cualquier entorno en red con responsabilidad compartida para la correcta administración de los archivos de datos lleva asociado un cierto grado de complejidad. Dicha complejidad se hace incontrolable si seguimos apegados a viejos modelos de trabajo propios de los primeros tiempos de la informática aplicada a la biblioteconomía y la archivística, tiempos, en cualquier caso, anteriores a la World Wide Web y el lenguaje XML. Tal y como lo describía Richard Feynman en relación a su propia disciplina, la física, «no puedes esperar que los viejos diseños funcionen en nuevas circunstancias». Se requiere un nuevo marco general de requisitos del sistema y una evaluación de los cambios culturales. Ello permitirá que infraestructuras de metadatos viables puedan adaptarse a archivos audiovisuales.
3.3 Infraestructura
3.3.1 No necesitamos un estándar de metadatos «discográficos»: aspirar a una solución específica para determinado ámbito es una limitación poco práctica. Necesitamos una infraestructura de metadatos que disponga de un núcleo de componentes compartido con otros ámbitos, cada uno de los cuales pueda a su vez acoger variaciones locales (mediante extensiones de esquema, por ejemplo) aplicables a las tareas de cualquier archivo audiovisual en concreto. Algunas de las cualidades esenciales para definir los requisitos estructurales y funcionales de los metadatos son las siguientes:
3.3.1.1 Versatilidad. En relación a los metadatos, el sistema debe ser capaz de incorporar, fusionar, indexar, resaltar y presentar al usuario metadatos provenientes de una variedad de fuentes descriptoras de una variedad de objetos. Debe ser también capaz de definir estructuras físicas y lógicas, donde la estructura lógica representa entidades intelectuales —como colecciones u obras— y la estructura física representa los medios o soportes físicos que constituyen la fuente de los objetos digitalizados. El sistema no debe estar sometido a un único esquema de metadatos: deben poderse mezclar esquemas con perfiles de aplicación (ver 3.9.8) adecuados a las demandas de cada archivo en particular, sin comprometer por ello la interoperatividad. El reto está en construir un sistema que admita la mayor diversidad sin complicaciones innecesarias para el usuario de bajo perfil, a la vez que permita acciones complejas a aquellos usuarios que requieran un mayor campo de maniobra.
3.3.1.2 Extensibilidad. Habilidad para admitir un amplio abanico de materias, tipos de documento (como imágenes y archivos de texto) y entidades de negocio (identificación de usuarios, licencias de uso, políticas de adquisición, etc.). Deben poderse aplicar, desarrollar o ignorar extensiones de metadatos sin arruinar el conjunto del sistema. En otras palabras, dado que la implementación de metadatos continúa siendo una ciencia inmadura, la experimentación debe ser posible.
3.3.1.3 Sostenibilidad. Capacidad de migración, mantenimiento asequible, usabilidad, relevancia y disponibilidad en el tiempo.
3.3.1.4 Modularidad. Los sistemas usados para crear, incorporar, fusionar, indexar o exportar metadatos deben ser modulares a fin de facilitar el reemplazo de componentes que realizan funciones concretas por otros, sin arruinar por ello el conjunto del sistema.
3.3.1.5 Granularidad o nivel de detalle. Los metadatos deben presentar el suficiente detalle como para permitir cualquier uso previsto. Es habitual que los metadatos no alcancen el suficiente nivel de detalle, y por contra es raro que un excesivo nivel de detalle impida alcanzar un objetivo determinado.
3.3.1.6 Liquidez. Escritura única, pero uso múltiple.12 La liquidez permitirá a los objetos digitales y a sus representaciones auto-documentarse a través del tiempo, de forma que los metadatos rendirán más al archivo en numerosos entornos en red y proporcionarán considerables ingresos para compensar la inversión inicial en tiempo y dinero.
3.3.1.7 Apertura y transparencia. El sistema de metadatos debe admitir la interoperatividad con otros sistemas. Para facilitar la extensibilidad, los estándares, protocolos y software incorporados deberán ser tan abiertos y transparentes como sea posible.
3.3.1.8 Estructura relacional (jerarquía / secuencia / proveniencia). El sistema debe expresar las relaciones de dependencia jerárquica relevantes (por ejemplo, en las escenas de una representación teatral y otras derivadas). En el caso de objetos digitales, debe permitir instanciaciones13 y mapeos precisos de los soportes originales de datos y sus contenidos intelectuales en relación con los archivos digitales. Todo ello permite asegurar la autenticidad del objeto archivado (Tennant: 2004).
3.3.2 Esta receta basada en la diversidad es a su vezen sí misma una forma de apertura. Si se apuesta opta por un estándar abierto propuesto por el W3C (World Wide Web Consortium) como XML (eXtensible Markup Language), un lenguaje de marcas ampliamente adoptado, ello no debe ser óbice para implementaciones particulares que incluyan una mezcla de estándares de intercambio como MXF (Material eXchange Format) y AAF (Microsoft’s Advanced Authoring Format)
3.3.3 Aun siendo un estándar abierto, la inclusión práctica de metadatos en el formato MXF se realiza habitualmente de un modo propietario.14 MXF aporta ventajas para la industria de la radiodifusión audiovisual (broadcasting) porque puede usarse para la transmisión profesional de contenido a tiempo real (streaming), mientras que otros contenedores permiten únicamente la descarga completa del archivo. El uso de MXF como contenedor de datos y metadatos es aceptable como medio de almacenamiento solo tras la sustitución de aquellos metadatos descritos mediante formatos propietarios por otros descritos en estándares abiertos.
3.3.4 Se ha escrito tanto sobre el formato XML que podría resultar fácil considerarlo una panacea. XML no es una solución «per se» aunque sí un excelente método de aproximación a la organización y re-utilización de contenidos, dada su enorme capacidad junto con una inagotable lista de herramientas y tecnologías aportadas por terceros en beneficio del reciclaje y la reutilización de datos. Como tal, XML se ha convertido en el estándar de facto para la representación de metadatos asociados a recursos disponibles en internet. Una década de euforia alrededor de XML viene hoy en día acompañada por el continuo desarrollo de instrumentos abiertos y también comerciales de edición del contenido generado en XML (ver 3.6.2).
3.3.5 Aunque el presente capítulo incluya referencias a formatos específicos de metadatos de uso común o que prometen serlo en el futuro, no pretenden ser en ningún caso prescriptivas. La observancia de las cualidades clave enumeradas en la sección 3.3.1 y el mantenimiento de información explícita, comprehensiva y puntual de todos los detalles técnicos, creación de datos y política de cambios, incluyendo fechas y responsables asociados, deberá permitir futuras migraciones y traslaciones sin cambios substanciales en la infraestructura de base. Una infraestructura de metadatos robusta deberá ser capaz de admitir nuevos formatos de metadatos mediante la creación o aplicación de instrumentos específicos de dicho formato, tales como tablas de equivalencia o crosswalks,15 o bien algoritmos para la traducción de metadatos de un esquema de codificación a otro de manera efectiva y precisa. Existe un buen número de tablas de equivalencia entre formatos como MARC, MODS, MPEG-7 Path, SMPTE y Dublin Core. El uso de tablas de equivalencia va más allá de la traslación de metadatos de uno a otro formato. Pueden ser usadas también para fusionar dos o más formatos de metadatos en un tercero, o en un conjunto de índices de búsqueda. Con un formato contenedor o de transferencia apropiado, como es METS, puede acomodarse casi cualquier formato de metadatos como MARC-XML, Dublin Core, MODS, SMPTE, etc. Además, esta infraestructura abierta permitirá a los archivos absorber, total o parcialmente, fichas de sus catálogos procedentes de sistemas informáticos heredados (anticuados pero todavía en uso) a la vez que ofrecer nuevos servicios basados en estos, como por ejemplo la recopilación y explotación de metadatos heredados (ver OAI-PMH, Open Archives Initiative Protocol for Metadata Harvesting).
12 «Usos» o «lecturas», a partir del inglés WORM – Write Once, Read Many (n. de los t.).
13 Anglicismo del ámbito informático que refiere a la creación de un objeto, «caso» o «ejemplo» concreto derivado de una clase o mode¬lo general de datos (n. de los t.).
14 Expresión del ámbito informático que se refiere a soluciones no abiertas, esto es, soluciones desarrolladas por compañías privadas cuyo uso se rige bajo licencia y con cierto coste económico (n. de los t.).
15 Aplicado a metadatos, el concepto de schema crosswalk se refiere a una tabla de equivalencias entre elementos o campos propios de esquemas de bases de datos distintos (n. de los t.).
3.4 Diseño - Ontologías
3.4.1 Una vez satisfechos estos requisitos constituyentes, el diseño de un sistema viable de metadatos tomará su forma a partir de un cierto modelo o esquema conceptual u ontología. Existen diferentes ontologías* relevantes en función de las operaciones que deban llevarse a cabo. Se recomienda el modelo CRM (Conceptual Reference Model, <http://cidoc.ics.forth.gr/>) del CIDOC para el sector del patrimonio cultural (museos, bibliotecas y archivos). El esquema FRBR (Functional Requirements for Bibliographic Records, http://www.loc.gov/cds/FRBR.html) será apropiado para un archivo mayormente formado por grabaciones de interpretaciones musicales o de obras literarias, mejor aún si se usa en combinación con RDA (Resource Description and Access) y DCMI (Dublin Core Metadata Initiative). A su vez, COA (Contextual Ontology Architecture, http://www.rightscom.com/Portals/0/Formal_Ontology_for_Media_Rights_Tran...) será la ontología adecuada cuando la gestión de derechos sea capital, así como también el estándar de gestión de derechos propuesto por la Motion Picture Experts Group, MPEG-21. RDF (Resource Description Framework http://www.w3.org/RDF/), una especificación versátil y relativamente ligera, cobra especial relevancia en entornos donde los recursos de la WWW se crean a partir del repositorio de archivos digitales; ello admite también aplicaciones populares como las RSS (Really Simple Syndication) para la redifusión de información (information feeds). Pueden hallarse nuevas propuestas en la mejora de la gestión e interpretación automatizada de metadatos entre las ontologías emergentes que usan OWL (Ontology Web Language). La definición y lectura de las ontologías definidas en lenguaje OWL puede realizarse fácilmente mediante la herramienta libre Protégé, de la Universidad de Stanford (Stanford University, http://protege.stanford.edu/). OWL puede utilizarse tanto para una definición simple de términos como para el modelado complejo basado en programación orientada a objetos.
* Según el World Wide Consortium (W3C) una ontología define los términos utilizados para describir y representar una cierta área del conocimiento. Usan ontologías la gente, las bases de datos y las aplicaciones que necesitan compartir la información de un cierto dominio (entendido simplemente como un área específica del conocimiento, como puedan ser la medicina, la industria mecánica, inmobiliaria, del automóvil, financiera, etc.). Las ontologías incluyen definiciones de conceptos básicos manejables por parte de máquinas (ordenadores) dentro de un dominio dado, así como las relaciones entre estos conceptos (obsérvese que tanto aquí como a lo largo de este documento, la definición no se utiliza en el sentido técnico dado por los expertos en lógica). Las ontologías codifican los conocimientos propios de un dominio y también conocimientos que abarcan varios dominios. De esta forma, permiten que el conocimiento sea reutilizable
3.5 Diseño - Grupos de elementos
3.5.1 El paso siguiente en el diseño de un sistema de metadatos consiste en establecer conjuntos de elementos. Se describen comúnmente tres categorías o conjuntos de metadatos:
3.5.1.1 Metadatos descriptivos, utilizados para el descubrimiento e identificación de un objeto.
3.5.1.2 Metadatos estructurales, utilizados para mostrar y recorrer un objeto en particular de cara a un usuario. Conllevan información sobre la organización interna del objeto, por ejemplo la secuencia prevista de eventos y relaciones con otros objetos, como imágenes o transcripciones de entrevistas.
3.5.1.3 Metadatos administrativos, depositarios de la información de administración del objeto (como por ejemplo, el dominio de identificadores o nombres que autorizan los metadatos mismos), fechas de creación o modificación del objeto, metadatos técnicos (como los formatos válidos del contenido, su duración, frecuencia de muestreo, etc.) o información de derechos y licencias. Esta categoría incluye por lo tanto datos esenciales para la preservación del objeto digital.
3.5.2 Estas tres categorías, descriptiva, estructural y administrativa, deben estar presentes con independencia de la operación que se realice, aunque puedan existir diferentes sub-categorías en cualquier fichero o instanciación. Así, cuando los metadatos admiten información de preservación —«información que soporta y documenta el proceso de preservación digital», según PREMIS— serán ricos en información sobre la procedencia del objeto, su autenticidad y las acciones llevadas a cabo sobre él. Si los metadatos, por otro lado, permiten la búsqueda y descubrimiento de datos, entonces una parte o todos los metadatos de preservación serán útiles para el usuario final (como garantes de autenticidad), aunque resultará más importante elaborar y destacar los datos descriptivos, estructurales y relativos a licencias y proporcionar los medios para transformar los metadatos en bruto en presentaciones intuitivas o en información que los usuarios externos en red puedan recopilar o con la que puedan interactuar. Obviamente, un objeto que no pueda encontrarse tampoco podrá conservarse, ni escucharse, ni será accesiblel: cuanto más inclusivos y completos sean los metadatos, tanto mejor.
3.5.3 Cada una de estas tres categorías de metadatos puede ser compilada por separado: los metadatos administrativos (técnicos) como subproducto del proceso de digitalización masiva, los metadatos descriptivos como el legado exportado desde una base de datos anterior y los metadatos de derechos como fruto progresivo de contratos de autorización de uso o licencias. Sin embargo, los resultados de todas estas compilaciones deben ser recopilados y mantenidos en una sola instancia u objeto de metadatos, o en un conjunto de ficheros de metadatos vinculados mediante las declaraciones apropiadas en relación con la preservación. Resulta esencial relacionar estos ficheros o piezas de metadatos mediante un esquema o DTD (Document Type Definition, definición de tipo de documento). En caso contrario, los metadatos seguirán siendo algo informe, una acumulación de datos comprensible para los humanos pero ininteligible para las máquinas.
3.6 Diseño - Codificación y esquemas
3.6.1 De la misma manera que las señales de audio se codifican en un fichero WAV, cuya especificación es conocida, también deben codificarse las categorías de metadatos. Para esta tarea recomendamos el formato XML, quizá combinado con RDF. Esta especificación deberá constar en la primera línea de cualquier instancia de metadatos como <?xml version=”“1.0” encoding=“UTF-8” ?>. Esta línea aporta por sí misma poco valor informativo: es como si dijéramos a un hipotético usuario que el folleto del CD que está leyendo está hecho de papel y que hay que sujetarlo de cierta manera. Las líneas que siguen proporcionan ese valor (tanto para máquinas como para usuarios humanos, recordemos), sobre los patrones previsibles y la semántica de los datos que integran resto del fichero. El resto de la cabecera del fichero de metadatos consiste por regla general en una secuencia de dominios de identificadores (namespaces) para otros estándares y esquemas (a menudo conocidos como «esquemas de extensión») invocados por el diseño de metadatos.
<mets:mets xmlns:mets=“http://www.loc.gov/standards/mets/”
xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xmlns:dc=“http://dublincore.org/documents/dces/”
xmlns:xlink=“http://www.w3.org/TR/xlink”
xmlns:dcterms=“http://dublincore.org/documents/dcmi-terms/”
xmlns:dcmitype=“http://purl.org/dc/dcmitype”
xmlns:tel=“http://www.theeuropeanlibrary.org/metadatahandbook/telterms.html”
xmlns:mods=“http://www.loc.gov/mods”
xmlns:cld=“http://www.ukoln.ac.uk/metadata/rslp/schema/”
xmlns:blap=“http://labs.bl.uk/metadata/blap/terms.html”
xmlns:marcrel=“http://www.loc.gov/loc.terms/relators/”
xmlns:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#type”
xmlns:blapsi=“http://sounds.bl.uk/blapsi.xml” xmlns:namespace-prefix=“blapsi”>
Figura 2: Conjunto de identificadores usados en el perfil METS de la British Library para registros sonoros
3.6.2 Estas especificaciones inteligentes se engloban en XML bajo el metalenguaje llamado esquema XML (XML schema),16 sucesor del metalenguaje DTD (Definition Type Document). Todavía es fácil hallar ejemplos de DTD dada la relativa simplicidad de su compilación. El esquema XML se define en un fichero propio con extensión* .xsd (XML Schema Definition) y deberá tener su propio dominio de identificadores (namespace) al cual puedan referirse las diferentes operaciones e implementaciones. Los esquemas requieren conocimiento experto para su compilación. Por fortuna existen herramientas de código abierto que permiten obtener automáticamente un esquema a partir de un documento XML bien estructurado. También existen herramientas que convierten ficheros XML en otros formatos habituales como .pdf o .rtf (Word). Por otro lado, el esquema también puede incorporar recursos idealizados para presentar los datos como un archivo XSLT. Los esquemas (y los dominios de identificadores) correspondientes a metadatos descriptivos se analizan con detalle en la sección 3.9, «Metadatos descriptivos — Perfiles de aplicación, Dublin Core (DC)».
3.6.3 Como resumen de todo lo anterior, podemos decir que un esquema XML o DTD describe una estructura XML que señala contenido textual en el formato propio de un fichero codificado en XML. El fichero (o instancia) contendrá uno o más dominios de nombres o identificadores que representarán el esquema extendido, responsable de ampliar posteriormente la estructura XML desarrollable.
16. Un esquema XML define la sintaxis de cualquier lenguaje basado en XML (n. de los t.).
3.7 Metadatos administrativos - Metadatos de preservación
3.7.1 La información descrita en esta sección forma parte de la categoría de metadatos administrativos. Dichos metadatos reiteran (o duplican) la información recogida en la cabecera del fichero de datos de audio y codifican la información operativa necesaria. Todo sistema informático puede reconocer un fichero y usarlo consecuentemente mediante la lectura de la información codificada en su cabecera y relacionando la extensión del fichero con un cierto tipo de software. Sin embargo, dado que las extensiones de ficheros son en el mejor de los casos indicadores ambiguos de la funcionalidad del fichero mismo, la información de cabecera y de extensión deberá también indicarse en un fichero aparte con el objetivo de facilitar la administración y el futuro acceso al fichero. Los campos descriptivos de información explícita, incluyendo tipos y versiones, pueden obtenerse automáticamente a partir de las cabeceras del fichero y usarse para rellenar los campos del sistema de administración de metadatos. Si hoy en día, o en el futuro, un sistema operativo no incluyera la capacidad de reproducir, pongamos por caso, un fichero con extensión *.wav o de leer un instancia en *.xml, el software en cuestión sería en definitiva incapaz de reconocer la extensión del fichero y no podría acceder a él ni determinar su tipo. Al explicitar esta información en un registro propio de metadatos, posibilitamos a futuros usuarios el uso de estos metadatos de preservación y la llave de acceso a los datos de información. La AES (Audio Engineering Society) ha publicado el estándar AES 57-2011 «Estándar para metadatos de audio - estructuras de objetos de audio para preservación y restauración» con el objeto de codificar esta aspiración.17
3.7.2 Aunque todavía en desarrollo, existen ya registros de formatos que serán de ayuda en el proceso de categorizar y validar formatos de ficheros como tarea previa a la captura de datos. Cabe citar PRONOM, un registro técnico en red mantenido por TNA (los National Archives del Reino Unido) que incluye formatos de ficheros y que puede ser usado en conjunción con otra herramienta del TNA llamada DROID (Digital Record Object Identification) capaz de realizar la identificación automatizada de diversos formatos de ficheros y de generar los consecuentes metadatos. La Universidad de Harvard en los Estados Unidos propone GDFR (Global Digital Format Registry) y JHOVE (JSTOR/Harvard Object Validation Environment) para la identificación, validación y caracterización de objetos digitales, con rendimiento comparable para la compilación de metadatos de preservación. En cualquier caso, la recopilación de información precisa sobre el formato de los ficheros es la clave para una exitosa preservación a largo plazo.
3.7.3 Lo más importante en definitiva es la cuidadosa valoración y archivo de todos los aspectos asociados a la preservación y la digitalización de los ficheros de audio, incluyendo todos los parámetros técnicos. Ello abarca todas las medidas subsecuentes llevadas a cabo para salvaguardar el documento de audio en el curso de su vida. Aunque mucha de la información de metadatos a la que nos referimos pueda ser adecuadamente cumplimentada en un estadio posterior, el registro de la creación del fichero de audio digital y los potenciales cambios que pueda sufrir su contenido debe hacerse en el mismo momento en que se produzca. Estos metadatos históricos tienen como función rastrear la integridad del objeto de audio. En el caso de usarse el formato BWF (Broadcast Wave Format) tales metadatos pueden ser registrados en el fragmento (chunk) BEXT de la cabecera del mismo fichero de audio, a modo de historial de la codificación. Esta información es parte vital de las recomendaciones que PREMIS hace sobre metadatos de preservación. La experiencia nos muestra que los ordenadores son capaces de producir copiosas cantidades de datos técnicos a partir del proceso de digitalización. A menudo convendrá destilar estos datos para sintetizar los metadatos dignos de conservar. Existen propuestas de categorías de elementos a este respecto como es el caso de AudioMD (http://www.loc.gov/rr/mopic/avprot/audioMD_v8.xsd), un esquema extendido desarrollado por la Library of Congress (EUA), o el AES audioObject XML schema, recientemente publicado dentro de los estándares AES 57-2011 y AES 60-2011.
3.7.4 En el proceso de digitalización de colecciones heredadas los esquemas pueden ser útiles para describir no solo el fichero digital, sino también el soporte físico original. En el momento de generar los metadatos descriptivos de un objeto debe evitarse toda posible ambigüedad: hay que describir la obra, su manifestación original y sus subsecuentes versiones digitales pero es necesario poder distinguir claramente lo que se describe en cada instancia. PREMIS distingue los diversos componentes en la secuencia de cambios asociándolos con acontecimientos (events), y vinculando los metadatos resultantes a lo largo del tiempo.
17 http://www.aes.org/publications/standards/search.cfm?docID=84 [último acceso noviembre 2011] (n. de los t.).
3.8 Metadatos estructurales - METS
3.8.1 Los medios de difusión basados en el tiempo son a menudo multimedia de cierta complejidad. Una grabación de campo puede consistir en una secuencia de acontecimientos (canciones, danzas, rituales) acompañados por imágenes y notas de campo. Una entrevista de historia oral de cierta duración distribuida en varios ficheros .wav puede ir acompañada de fotografías de los participantes en la entrevista y de transcripciones escritas o análisis lingüísticos. Los metadatos estructurales proporcionan un inventario de todos los ficheros relevantes además de explicaciones sobre relaciones externas e internas, incluyendo preferencias en la secuenciación de la información (por ejemplo, los actos y escenas de una grabación operística). El estándar METS (Metadata Encoding and Transmision Standard, actualmente en su versión 1.9), con sus secciones de mapa estructural (mapestr) y de agrupación de ficheros está demostrando sobradamente su capacidad en contextos audiovisuales (ver figura 3).
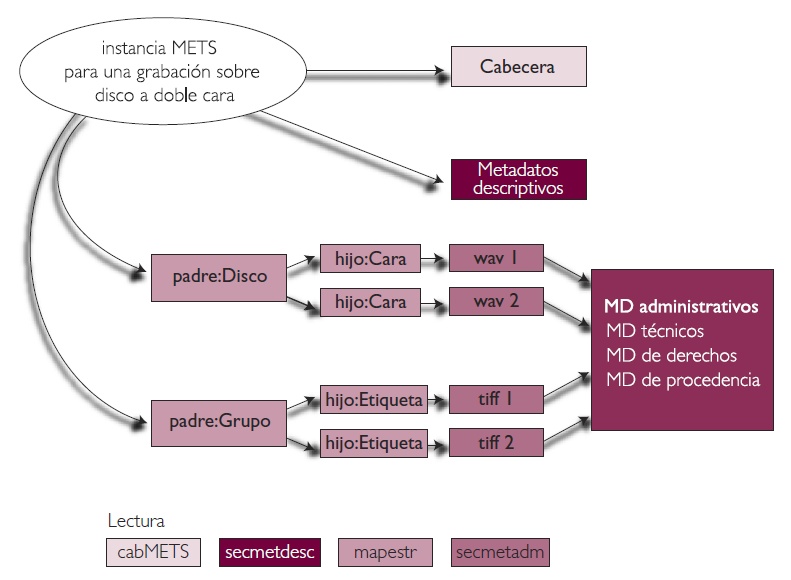
Fig 3: componentes de una instancia METS y un posible conjunto de relaciones entre ellos
3.8.2 Los componentes o secciones de una instancia METS son:
3.8.2.1 Una cabecera que describe el objeto METS, con información, por ejemplo, sobre quién, cuándo y para qué fue creado el objeto. La información de cabecera hace posible la correcta administración del fichero METS.
3.8.2.2 Una sección de metadatos descriptivos, que describen la fuente de información representada por el objeto digital y permite su descubrimiento.
3.8.2.3 Un mapa estructural, representado por las hojas y detalles individuales, encargado de ordenar los ficheros digitales que componen el objeto en una jerarquía consultable.
3.8.2.4 Una sección de ficheros de contenidoque declara qué ficheros digitales constituyen el objeto. Los ficheros pueden estar embebidos en el mismo objeto o únicamente mencionados.
3.8.2.5 Una sección de metadatos administrativos que contiene información sobre los ficheros digitales declarados en la sección de ficheros de contenido. Esta sección se subdivide en:3.8.2.5.1 metadatos técnicos que especifican las características técnicas del fichero;
3.8.2.5.2 metadatos de origen que especifican la fuente de la captura (por ejemplo, una captura directa o una transparencia de 4x5 reformateada);
3.8.2.5.3 metadatos de procedencia digital que especifican los cambios que el fichero ha sufrido desde su origen;
3.8.2.5.4 metadatos de derechos que especifican las condiciones de acceso legal al objeto digital.3.8.2.6 Las secciones de metadatos técnicos, metadatos de origen y metadatos de proveniencia digital aportan en conjunto la información pertinente para la preservación digital.
3.8.2.7 Para ser exhaustivos cabe mencionar la sección de comportamiento, no recogida en la figura 3, que asocia ficheros ejecutables con un objeto METS. Por ejemplo, un objeto METS puede depender de un cierto código para su acceso (o visionado), y la sección de comportamiento puede hacer referencia ese código.
3.8.3 Puede suceder que los metadatos estructurales necesiten representar otros objetos relacionados con la empresa o institución:
3.8.3.1 información de usuario (autentificación)
3.8.3.2 derechos y licencias (cómo puede ser usado un objeto digital)
3.8.3.3 políticas (cómo realiza el archivo la selección de objetos)
3.8.3.4 servicios (derechos y autorizaciones de copia)
3.8.3.5 organizaciones (colaboraciones, partes interesadas, fuentes de financiación)
3.8.4 Estos objetos adicionales pueden ser representados por ficheros que remitan a direcciones específicas o URLs (Uniform Resource Locators). Los metadatos pueden incluir notas aclaratorias para usuarios humanos.
3.9 Metadatos Descriptivos — Perfiles de Aplicación, Dublin Core (DC)
3.9.1. La mayor parte de los esfuerzos dedicados a los metadatos por parte del sector de la archivística se han concentrado en los metadatos descriptivos, como una rama natural de la catalogación tradicional. Sin embargo, parece claro que dedicar demasiada atención a esta área (desarrollando, por ejemplo, etiquetas descriptivas y vocabularios controlados hasta un nivel de refinamiento muy específico) a expensas de otras consideraciones ya descritas más arriba puede resultar en limitaciones o defectos del sistema en su conjunto. La figura 4 nos muestra las variadas interdependencias que deben establecerse, donde los metadatos descriptivos son solo una de las diversas subcategorías entre todos los elementos en juego.
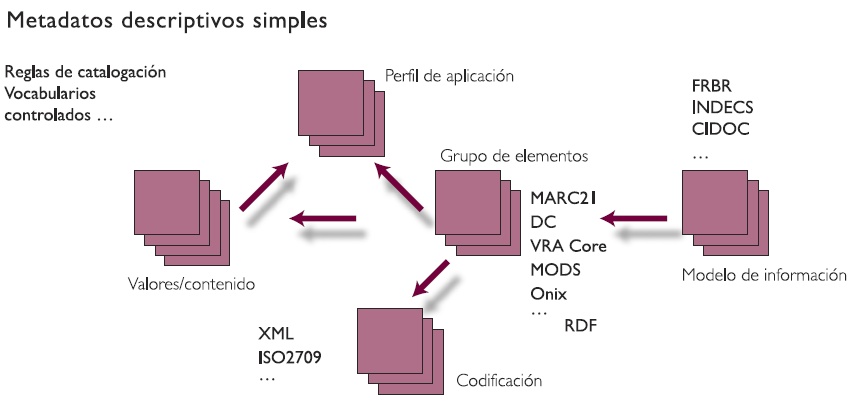
Fig 4: Metadatos descriptivos simples (cortesía de Dempsey, libro elemental de CLIR/DLF, 2005)
3.9.2 La interoperatividad debe ser un componente clave en cualquier estrategia de metadatos: los sistemas complejos creados por cuenta propia por un equipo voluntarioso para un repositorio de archivo son la receta perfecta para una baja productividad, alto coste y mínimo impacto. El resultado será una industria artesanal de metadatos incapaz de crecer. El ámbito de los metadatos descriptivos es sin duda un ejemplo clásico de la máxima de Richard P. Gabriel «lo peor es mejor». Gabriel predijo correctamente que, de dos lenguajes de programación, uno elegante pero complejo y el otro torpe pero simple, el segundo se propagaría a mayor velocidad y en consecuencia, un mayor número de usuarios se interesaría en mejorar aspectos de este segundo lenguaje en detrimento del primero. Un ejemplo de ello lo constituye la rápida y exitosa adopción de Dublin Core (DC), inicialmente considerado una opción improbable por parte de los profesionales a causa de su palmaria simplicidad.
3.9.3 La misión de la DCMI (Dublin Core Metadata Initiative) ha sido facilitar el hallazgo de recursos a través de internet por medio del desarrollo de estándares de metadatos que permitan el descubrimiento entre diferentes dominios de conocimiento, definiendo marcos para la interoperatividad de conjuntos de metadatos y facilitando el desarrollo de metadatos específicos para una comunidad o disciplina concretas consistentes con esos propósitos. Se trata de un vocabulario de solamente quince elementos con los que describir recursos, y cubre con economía de medios las tres categorías de metadatos. Ninguno de estos elementos es obligatorio: todos ellos son repetibles, aunque quienes los implementen puedan aportar sus propias especificaciones en perfiles de aplicación (ver más adelante la sección 3.9.8). El nombre de «Dublin» se debe a su origen en el taller organizado en la ciudad de Dublin, Ohio (Estados Unidos) en 1995. El término «core», traducible como centro o núcleo, responde a que sus elementos son genéricos y de amplio alcance, utilizables para describir un gran abanico de recursos. El uso de Dublin Core ha gozado de un amplio respaldo durante más de una década y sus quince elementos descriptores han sido formalmente avalados en los siguientes estándares: ISO Standard 15836-2003 de febrero de 2003 [ISO15836 http://dublincore.org/documents/dces/#ISO15836] NISO Standard Z39.85-2007 de mayo de 2007 [NISO Z3985 http://dublincore.org/documents/dces/#NISO Z3985 ] e IETF RFC 5013 de agosto de 2007 [RFC 5013 http://dublincore.org/documents/dces/#RFC 5013].
A continuación, el cuadro 1 lista los quince elementos de DC con sus definiciones oficiales abreviadas y sus posibles interpretaciones en un contexto audiovisual.
| Elemento DC | Definición DC | Interpretación audiovisual |
|---|---|---|
| Título | Nombre dado al recurso | Título principal asociado a la grabación |
| Tema | Tema del recurso | Principales temas tratados |
| Descripción | Informe sobre el recurso | Notas explicativas, resumen de entrevistas, descripciones de contextos culturales o ambientales, listado de contenidos |
| Creador | Entidad o persona responsable principal de la creación del recurso | Nombre del fichero, no de los autores o compositores de las obras grabadas |
| Editor | Entidad o persona responsable de hacer efectivo el acceso al recurso | No se trata de quien publica el documento original previo a la digitalización. Habitualmente el editor es el mismo que el creador |
| Contribuyente | Entidad o persona responsable de contribuciones al recurso | Cualquier persona o fuente de sonido mencionados. Debe indicarse el papel que tiene (por ejemplo, ejecutante, técnico de sonido) |
| Fecha | Fecha o periodo de tiempo asociado con un evento en el ciclo de vida de un recurso | No la fecha de la grabación o producción, sino una fecha asociada al recurso en cuestión |
| Tipo | Naturaleza o género del recurso | Dominio del recurso, pero no su género musical. Por ejemplo «sonido», pero no «jazz» |
| Formato | Formato del fichero, medio físico o dimensiones del recurso descrito | Formato del fichero digital, no del soporte físico original |
| Identificador | Referencia inequívoca a un recurso en un contexto dado | Posiblemente el Identificador Uniforme de Recurso o URI del fichero de sonido |
| Fuente | Recurso relacionado del cual deriva el recurso descrito | Referencia a un recurso del cual deriva el recurso actual |
| Idioma | Idioma del recurso | Idioma del recurso |
| Relación | Recurso relacionado | Referencia a objetos relacionados |
| Cobertura | El tema espacial o temporal del recurso, la aplicación espacial del recurso o la jurisdicción bajo la cual el recurso es relevante | Lo que la grabación ejemplifica, por ejemplo una característica cultural, como un dialecto o canciones tradicionales |
| Derechos | Información sobre los derechos legales que afectan al uso del recurso. | Información sobre los derechos legales que afectan al uso del recurso. |
Cuadro 1: Los 15 elementos DC
3.9.4 Los elementos de Dublin Core han sido expandidos para abarcar nuevas propiedades. Estas propiedades se conocen como términos DC. Un cierto número de estos elementos o «términos» adicionales resultan útiles para la descripción de medios basados en la reproducción temporal:
| Elemento DC | Definición | Interpretación audiovisual |
|---|---|---|
| Alternativa | Cualquier forma del título utilizada como sustituto o alternativa al título formal del recurso. | Título alternativo, por ejemplo, traducción, seudónimo u ordenación alternativa de los elementos de un título genérico |
| Extensión | Tamaño o duración del recurso | Tamaño y duración del fichero |
| extensiónOriginal | Manifestación física o digital del recurso | Tamaño o duración de las grabaciones del recurso original |
| Espacial | Características espaciales del contenido intelectual del recurso | Ubicación de la grabación, incluyendo coordenadas topográficas para interfaces de mapas |
| Temporal | Características temporales del contenido intelectual del recurso | Ocasión en que se realizó la grabación |
| Creación | Fecha de creación del recurso | Fecha de grabación o cualquier otra fecha significativa en el ciclo de vida de una grabación |
Cuadro 2: Términos DC (selección)
3.9.5 Los implementadores de DC pueden escoger entre los quince elementos en su versión original, dc:variant (como por ejemplo en http://purl.org/dc/elements/1.1/creator) o bien entre los términos de la variante extendida, dcterms:variant (por ejemplo en http://purl.org/dc/terms/creator) en función de los requisitos de cada aplicación. Con el tiempo se espera —y a ello anima DCM— un uso de los términos semánticamente más precisos dcterms:properties, más aún si el marco RDF es parte de la estrategia de metadatos, puesto que estos términos satisfacen mejor las recomendaciones profesionales para el procesado automatizado de metadatos.
3.9.6 Aun en su forma expandida, DC adolece del grado de detalle requerido en un archivo especializado en contenido audiovisual. El elemento Contribuyente, por ejemplo, deberá explicitar el papel desempeñado en el proceso concreto de grabación para evitar, por ejemplo, la habitual confusión entre intérpretes y compositores, o entre actores y dramaturgos.
<dcterms:contribuyente>
<marcrel:CMP>Beethoven, Ludwig van, 1770-1827</marcrel:CMP>
<marcrel:INT>Quatuor Pascal</marcrel:INT>
</dcterms:contribuyente>
<dcterms:contribuyente>
<marcrel:ORA>Greer, Germaine, 1939- (mujer)</marcrel:ORA>
<marcrel:ORA>McCulloch, Joseph, 1908-1990 (hombre)</marcrel:ORA>
</dcterms:contribuyente>
El primer ejemplo etiqueta «Beethoven» como compositor (CMP) y « Quatuor Pascal» como intérprete (INT). El segundo ejemplo etiqueta a ambos contribuyentes, Greer y McCulloch, como oradores o conferenciantes (ORA) aunque no aporta el detalle suficiente como para determinar quién es el entrevistador y quién el entrevistado. Esta información debería especificarse en algún otro campo de metadatos como la Descripción o el Título.
3.9.7 A este respecto podrían preferirse otros esquemas, o incluirlos como una extensión adicional de esquema (tal y como se vio en la figura 2). Por ejemplo MODS (Metadata Object Description Schema o esquema de descripción de objetos de metadatos, http://www.loc.gov/standards/mods) permite mayor detalle en los nombres y su vinculación con ficheros de autoridad, reflejo de su derivación del estándar MARC:
name
Subelements:
namePart
Attribute: type (date, family, given, termsOfAddress)
displayForm
affiliation
role
roleTerm
Attributes: type (code, text); authority
(see: www.loc.gov/marc/sourcecode/relator/relatorsource.html)
description
Attributes: ID; xlink; lang; xml:lang; script; transliteration
type (enumerated: personal, corporate, conference)
authority (ver: www.loc.gov/marc/sourcecode/authorityfile/authorityfilesource.html)
3.9.8 En el marco de METS resulta admisible la inclusión de más de un conjunto de metadatos descriptivos en función del cumplimiento de diferentes propósitos. Tendríamos por ejemplo un conjunto que sigue DC (para el cumplimiento del protocolo OAI-MPH) además de un conjunto más sofisticado adscrito a MODS para el cumplimiento de otras iniciativas y en particular el intercambio de registros con sistemas codificados en MARC. La capacidad de incorporar diferentes estándares es una de las ventajas de METS.
3.9.9 DC sigue desarrollándose bajo el control del DCMI, Dublin Core Metadata Initiative. Por un lado, su capacidad para entrelazar recursos se ve reforzada mediante su interrelación más estrecha con herramientas semánticas en la red tales como RDF (ver Nilsson et al, DCMI 2008). Por otro lado, la asociación formal desde 2009 con RDA (Resource Description & Access http://www.collectionscanada.gc.ca/jsc/rda.html) incrementa su relevancia en el sector del patrimonio. Dado que RDA se considera el sucesor de las Anglo-American Cataloguing Rules, este particular desarrollo puede comportar sustanciales implicaciones estratégicas para los archivos audiovisuales que forman parte de bibliotecas nacionales y universitarias. Para los archivos de radiodifusión y televisión también son significativos otros desarrollos basados en DCMI. En el momento de la redacción de este documento, la EBU (Unión Europea de Radio y Televisión) completa el desarrollo de EBU CORE Metadata Set, basado en — y compatible con — Dublin Core.
3.9.10 Puede darse el caso de que el archivo desee modificar (expandir, adaptar) el conjunto nuclear de metadatos. Estos conjuntos modificados, basados en uno o más esquemas de elementos o identificadores (por ejemplo MODS y IEEE LOM así como también DC) se conocen como perfiles de aplicación. Todos los elementos en un perfil de aplicación se obtienen de recursos externos, de esquemas de elementos distintos. Si los implementadores desean crear «nuevos» elementos no categorizados en ningún otro esquema, como por ejemplo roles de contribuyente no disponibles en el grupo de relatores de MARC (agentes no humanos como por ejemplo especies, máquinas, entornos) deben entonces crear su propio esquema de elementos y asumir la responsabilidad de «declarar» y mantener dicho esquema.
3.9.11 Los perfiles de aplicación incluyen una lista de los identificadores directivos junto con sus localizadores uniformes (preferiblemente URLs permanentes, PURLs). Estos URLs se replican en cada instancia o entrada de metadatos. A estos URLs les siguen una lista de cada elemento de datos junto con sus valores admitidos y tipo de contenido. Esto puede referirse a reglas internas o adicionales y a vocabularios controlados, como tesauros o nombres y géneros de instrumentos, ficheros de autoridad de nombres de personas y materias. El perfil de aplicación deberá especificar también esquemas obligatorios para elementos específicos como fechas (año-mes-día) y coordenadas geográficas y estas representaciones estandarizadas de localización y tiempo serán capaces de mostrar mapas y líneas de tiempo como dispositivos de recuperación no textual.
| Nombre el término | Título |
|---|---|
| URI (Identificador Uniforme de Recurso) | http://purl.org/dc/elements/1.1/title |
| Etiqueta | Título |
| Definido por | http://dublincore.org/documents/dcmi-terms/ |
| Definición de la fuente | Nombre dado al recurso |
| Definición en BLAP-S | Título de una obra o de un componente de una obra |
| Elementos de la fuente | Habitualmente un título es un nombre por el cual se conoce formalmente a la fuente |
| Comentarios en BLAP-S | Si no hay título disponible, construir uno que se derive del recurso o proveedor [no hay título]. Seguir las prácticas habituales de catalogación para títulos en otros idiomas usando el refinamiento «alternativo». Cuando los datos se deriven del catálogo del Sound Archive el título equivaldrá a uno de los siguientes campos de título en el siguiente orden jerárquico: título de la obra (1), título del ítem (2), título de la colección (3), título del producto (4), especie original (5), titulo de difusión (6), título corto (7), serie publicada (8), serie no publicada (9) |
| Tipo de término | Elemento |
| Refinamientos | |
| Refinado por | Alternativo |
| Tiene esquema de codificación | |
| Obligación | Obligatorio |
| Ocurrencia | No repetible |
Figura 5: Parte del perfil de aplicación de DC de la British Library para el sonido (BLAP-S)
Espacios de nombres usados en este perfil de aplicación:
Términos de metadatos
DCMI: http://dublincore.org/documents/dcmi-terms/
RDF (Resource Description Framework): http://www.w3.org/RDF/
Elementos MODS: http://www.loc.gov/mods
TérminosTEL: http://www.theeuropeanlibrary.org/metadatahandbook/telterms.html
Términos BL http://labs.bl.uk/metadata/blap/terms.html
MARCREL: http://www.loc.gov/loc.terms/relators/
3.9.12 El perfil de aplicación incorpora o toma por lo tanto elementos de un diccionario de datos (un fichero que define la organización básica de una base de datos hasta el nivel de campos individuales y tipos de campos) o hasta de diferentes diccionarios de datos que pueden ser mantenidos por un único archivo o compartidos por una comunidad de archivos. El diccionario de datos PREMIS (http://www.loc.gov/standards/premis/v2/premis-2-0.pdf, actualmente en su versión 2), referido exclusivamente a metadatos de preservación, es uno a los que más se acude. Sus numerosos elementos se conocen como «unidades semánticas». Los metadatos de preservación aportan explicaciones sobre la proveniencia, actividad de preservación y características técnicas de los datos, y ayuda en la verificación de la autenticidad de un objeto digital. El Grupo de Trabajo de PREMIS presentó su Diccionario de datos para metadatos de preservación en junio de 2005 y recomienda su uso en todos los repositorios de preservación sean cuales sean el tipo de material archivado y las estrategias de preservación desarrolladas.
3.9.13 Mediante la definición de perfiles de aplicación y, lo que es más importante, mediante su exposición pública, los implementadores pueden compartir información sobre sus esquemas con el fin de colaborar en tareas universales como la preservación a largo plazo.
3.10 Fuentes de metadatos
3.10.1 Los archivos no deberían pretender crear por ellos mismos, a partir de cero, toda la estructura de metadatos descriptivos (es decir, a la vieja usanza). Dado el ciclo de vida inherente y entrelazado entre recursos y metadatos, tal idea resulta impracticable. Existen diversas fuentes de metadatos, especialmente en lo concerniente a metadatos descriptivos, que deben explotarse con el fin de reducir costes y generar riqueza a través de la diversificación de las tipologías de entrada. Hay tres principales fuentes de metadatos descriptivos: profesionales, contributivas e intencionales (Dempsey). Las tres pueden ser desplegadas en paralelo.
3.10.2 Las fuentes profesionales se alimentan del valor perenne de las bases de datos históricas, ficheros de autoridad y vocabularios controlados, útiles para materiales publicados o replicados. Incluyen bases de datos industriales, así como catálogos de archivo. Tales fuentes, especialmente catálogos de archivo, son notoriamente incompletos e incapaces de interoperar sin la ayuda de sofisticados programas de conversión y complejos protocolos. En la industria de la radiodifusión y la grabación —en el sector audiovisual clásico en general— hay casi tantos estándares en activo como bases de datos independientes. La falta de un identificador universal para el sector audiovisual, como es el código ISBN para el sector del libro impreso, es un continuo obstáculo, y tras décadas de desarrollo discográfico no existe todavía consenso sobre qué constituye un ítem de catálogo: la unidad intelectual ¿es una pista individual, o bien una secuencia de pistas, como sucede con una obra musical o literaria dividida en varias secciones? ¿Es el conjunto de pistas en un soporte único o en un conjunto de soportes, en otras palabras, es el soporte físico la unidad de catalogación? Evidentemente, una agencia que haya optado por una definición de mayor detalle encontrará mucho más sencilla y exitosa la exportación de sus metadatos históricos a su nueva infraestructura de metadatos. Las exportaciones de datos doblemente cautas basadas en Z39.50 (http://www.loc.gov/z3950/agency, protocolo para la obtención categorizada de información) y SRW/SRU (protocolo para la búsqueda y obtención de información vía URLs estandarizadas, con respuesta estandarizada en XML) continuarán aportando un cierto grado de éxito, como lo hará la habilidad de los ordenadores para recolectar metadatos a partir de un recurso central. Sin embargo será más efectivo apostar por la producción compartida de recursos que identifiquen y describan nombres, materias, lugares, periodos de tiempo y obras.
3.10.3 Las fuentes contributivas se alimentan del contenido generado por los propios usuarios. Un fenómeno destacable en los últimos tiempos es la aparición de muchos sitios en internet que promueven la generación, agregación y extracción de datos por parte de usuarios, y se sirven de esos datos para priorizar, recomendar y relacionar recursos. Entre estos encontramos, por ejemplo, YouTube y LastFM. Tales sitios web son valiosos por el hecho de revelar relaciones entre gente y entre gente y recursos, así como información sobre los recursos mismos. Las bibliotecas han empezado a experimentar con estas propuestas y se vislumbran ventajas palpables en el hecho de permitir a los usuarios el desarrollo de metadatos procedentes de fuentes profesionales. La llamada web 2.0, con sus características orientadas a facilitar la contribución y sindicación de datos por parte de los usuarios, está convirtiendo estas prácticas en habituales en los sistemas de gestión de contenidos.
3.10.4 Las fuentes intencionales se basan en la recolección de datos a partir del uso reiterado de los recursos, con la intención de mejorar el descubrimiento de los mismos recursos. El concepto se toma prestado del sector comercial: las recomendaciones del portal Amazon, por ejemplo, basadas en selecciones de compra acumuladas. Se pueden usar algoritmos similares para jerarquizar objetos en un recurso. Este tipo de datos son ya un factor clave para el éxito de ciertos sitios web y han abierto el camino para la administración de cantidades ingentes de datos de información compleja.
3.11 Necesidades de desarrollo futuras
3.11.1 A pesar de lo avanzado hasta ahora, la administración de metadatos sigue siendo una ciencia inmadura. Este capítulo espera haber mostrado cómo un cierto número de piedras angulares (diccionarios de datos, esquemas, ontologías, codificaciones) han sido ya ubicadas para facilitar a los investigadores la accesibilidad a contenido audiovisual, así como la tan ansiada aspiración de nuestro gremio de salvaguardarlo sin deterioro. Para lograr un progreso aún más rápido será necesario establecer bases comunes entre los sectores público y comercial, así como entre las diferentes categorías de archivos audiovisuales, cada uno de los cuales se ha mantenido ocupado concibiendo su propios instrumentos y estándares.
3.11.2 Se ha logrado un cierto éxito con la obtención automática de metadatos a partir de los recursos. Debemos hacer más, habida cuenta que los actuales procesos manuales no permiten una buena escalabilidad. La producción de metadatos no parece sostenible a menos que se reduzcan costes en el proceso. «No deberíamos añadir coste y complejidad, que es lo que tiende a suceder cuando el desarrollo se basa en múltiples canales buscadores de consenso que responden a los imperativos de solo una parte del entorno de servicio» (Dempsey: 2005).
3.11.2 El problema de la reconciliación entre bases de datos, esto es, la capacidad de un sistema para entender que ciertos ítems son semánticamente idénticos aun cuando se representen de maneras diferentes, continúa siendo una cuestión abierta. Se está investigando bastante en este sentido, aunque la solución global está todavía por llegar. La cuestión es también muy importante para la gestión de la persistencia en el modelo OAIS, como demuestra el siguiente ejemplo. La expresión semántica de que Wolfgang Amadeus Mozart es el compositor de la mayor parte del Requiem (K.626) se representa de manera totalmente diferente en el modelo conceptual FRBR (Functional Requirements for Bibliographic Records) comparado con una lista simple de términos de DCMI (Dublin Core). En DCMI «Compositor» es un refinamiento de «Contribuyente» y «Mozart» es su propiedad; en FBRB en cambio «Compositor» es una relación entre una persona física y una obra artística. El uso de vocabularios controlados es también una forma de asegurar que W.A. Mozart representa a la misma persona que Mozart.